
leveldb 源码分析 [6] —— Cache
leveldb 笔记一:缓存系统 Cache
LRUHandle
An entry is a variable length heap-allocated structure. 一个变长结构体对象,它被分配在堆上。
LRUHandle 是 双向循环链表(为了实现 LRU 替换策略)的节点。在该链表上按访问时间排序。
变长体现在哪里?首先看它的结构体定义:
1 | struct LRUHandle { |
除了 key_data 字段,其他都是固定长度的。因此可以这样认为,LRUHandle 是一个尾部长度可变的对象。
存疑一:为什么不是 char* key_data 而是直接把 key 存储在 LRUHandle 中呢?为什么用 char key_data[1] 而不是 柔性数组 char key_data[]
Note: GCC 由于对 C99 的支持,允许定义 char key_data[ ] 这样的柔性数组(Flexible Array)。但是由于 c++ 标准并不支持柔性数组的实现,这里定义为 key_data[1],这也是 c++ 中的标准做法。
回答一:如果存的是指针,那么指针指向的 key 对象就也需要进行 malloc 分配空间,那么带上 LRUHandle 则需要 malloc 两次。如果把 key 对象和 LRUHandle 放在一块,只需要 malloc 一次,而 malloc 是有可能会陷入内核的,因此尽量减少 malloc 的次数,可以加快速度。
HandleTable
它其实就是一个简单的 HashTable 先看它的成员变量:
1 | class HandleTable { |
它使用开链法来解决 hash 冲突,总共设置 length_ 个 bucket,每个 bucket 就是一条单向链表,每条链表的节点就是 LRUHandle,这里可以和 LRUHandle 结构体中的 next_hash 字段结合起来。elems_ 就表示了 HandleTable 中总共有多少个元素,可以用于之后对 hash table 进行 Resize。
刚开始 hash table 自然是空的,因此直接调用 Resize,进行初始化。
Resize 需要考虑两种情况:
- hash table 为空时进行 Resize
- hash table 不为空时进行 Resize
1 | void Resize() { |
其实要看懂这段代码,唯一的难点是理解 LRUHandle** 到底是个什么东西,它其实就是一个 数组,数组中的每一个元素就是 LRUHandle 链表头节点的指针。然后在 while 循环中使用的是 链表的 头插法
接下来就是 Insert、Remove、Lookup 和 FindPointer,这里只需要看懂 FindPointer,其他的就自然看懂了。
1 | LRUHandle** FindPointer(const Slice& key, uint32_t hash) { |
ptr 是单向链表头节点,这个在之前已经说过了。在这里 LRUHandle** ptr = &list_[hash & (length_ - 1)]; 的确是这样的,但是在 while 循环中,ptr 已经不是这个意思了,它是 LRUHandle::next_hash 的地址;而 *ptr 仍然是指向 LRUHandle 节点的指针。自然,返回值也就是 LRUHandle::next_hash 的地址。因此在后续的 Insert、Remove 操作中,我们直接修改 ptr 所指地址处的值(也就是 LRUHandle::next_hash 的值)就可以达到我们需要的效果。
LRUCache
逻辑上,设计成列表,一个 Hash Table。两个列表用于存储 LRUHandle 节点,由循环双向链表来实现 LRU 替换策略,Hash Table 用于加速对节点的索引 O(1),用开链法解决 hash 冲突。
两链表,一哈希表:
- LRUHandle lru_ GUARDED_BY(mutex_); // 虚拟头节点
- LRUHandle in_use_ GUARDED_BY(mutex_); // 虚拟头节点
- HandleTable table_ GUARDED_BY(mutex_);
这里两个链表的关系是这样的,我们可以把 LRUCache 内的 Handle 分为四个状态:
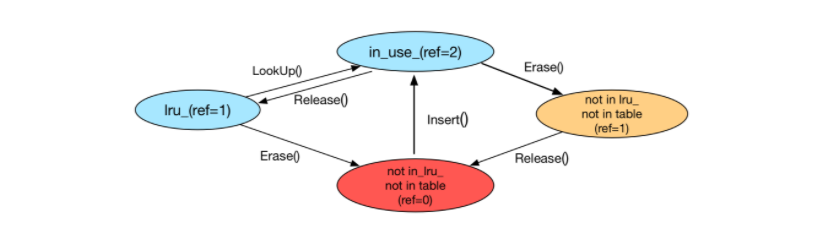
- *in use (ref=2)*:该 Handle 在 HandleTable 中,并且串联在
in_use_链表中;由于该 Handle 既被外部使用,也被in_use_链表使用,因此有 ref=2; - *in lru (ref=1)*:该 Handle 在 HandleTable 中,并且串联在
lru_链表中;由于该 Handle 只被lru_引用,因此 ref=1; - *not in lru, not in table (ref=1)*:该 Handle 不在链表中也不再 HandleTable 中,但是仍然被外部引用而未释放,因此 ref=1;
- *not in lru, not in table (ref=0)*:该 Handle 不在链表中也不再 HandleTable 中,也不被外部使用,因此 ref=0;
在 LRUCache 析构时,必须保证 in_use 链表为空,也就是说没有被外部引用并且在链表中(即状态 1)的节点。之后,就可以对 lru_ 链表中的节点逐一 调用 Unref 来让节点的 deleter 去释放资源。
LRUCache 类中有一点很符合 morden c++ 的写法,也很值得我学习:
1 | class LRUCache { |
在 公共接口 中,用 Cache::Handle* 来表示 LRUHandle*;而在 私有接口 中,仍旧保留 LRUHandle*;这其实是向外隐藏了 LRUHandle*;
ShardedLRUCache
这个类其实就是用来减少 race condition 的,因为 leveldb 缓存系统支持并发,因此要对每一个 LRUCache 加互斥锁,如果只有一个 LRUCache 的话,虽然在外部看来是并发访问了,但是由于为了保证线程安全,在方法临界区内所有访问都被串行化了。但是如果对 Cache 进行分片,也就是增加 LRUCache 的数量(其实就是搞一个 LRUCache 数组),通过 hash 的方式索引到具体某一个 LRUCache 进行访问,这样 LRUCache 之间是可以并行访问并保证线程安全的,这就提高了整个缓存系统的并发性。
1 | static const int kNumShardBits = 4; |