
leveldb 源码分析 [4] —— SSTable
LevelDB 源码分析【4】—— SSTable
SSTable 是一种文件的存储格式,MemTable 中的数据,最终都会被序列化然后压缩持久化存储到稳定介质中去(磁盘);
SSTable 物理结构
SSTable 文件被划分成固定大小的块(一般每块为 4KB),这里我就有问题了:为什么一个文件要被划分出固定的块呢?
每一个块由三部分组成:
- Data:经过 序列化 + 压缩 后的数据
- Compression Type:压缩算法类型,leveldb 默认使用 Snappy 算法进行压缩
- CRC:冗余校验校验码,校验范围包括 Data 和 Compression Type

SSTable 逻辑结构
在逻辑上,根据功能不同,leveldb在逻辑上又将sstable分为:
- data block: 用来存储key value数据对;
- filter block: 用来存储一些过滤器相关的数据(布隆过滤器),但是若用户不指定leveldb使用过滤器,leveldb在该block中不会存储任何内容;
- meta Index block: 用来存储filter block的索引信息(索引信息指在该sstable文件中的偏移量以及数据长度);
- index block:index block中用来存储每个data block的索引信息;
- footer: 用来存储meta index block及index block的索引信息;
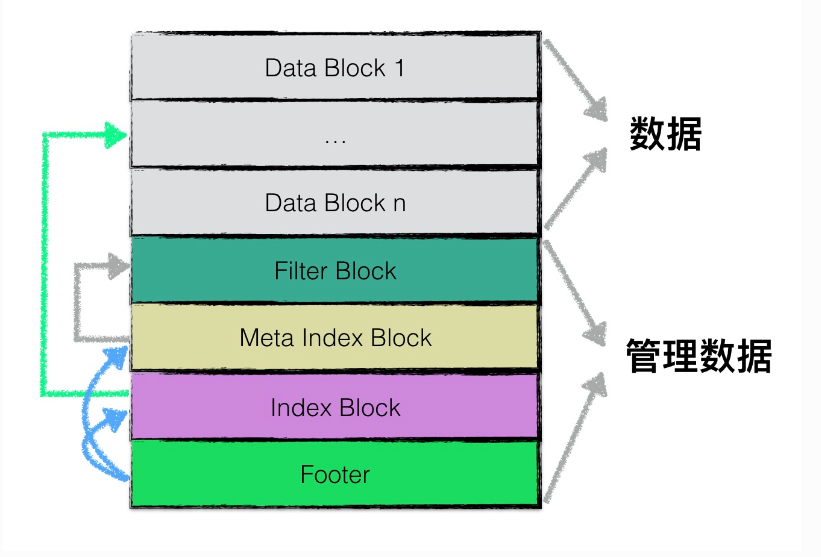
注意,1-4类型的区块,其物理结构都是如1.1节所示,每个区块都会有自己的压缩信息以及CRC校验码信息。
想要了解各类 block 的具体建造方式,可以查看 table/block_builder.h 和 table/block_builder.cc
data block
data block 中存储的数据是 leveldb 中的 key value 键值对。其中一个 data block 中的数据部分(不包括压缩类型、CRC校验码)按逻辑又以下图进行划分:
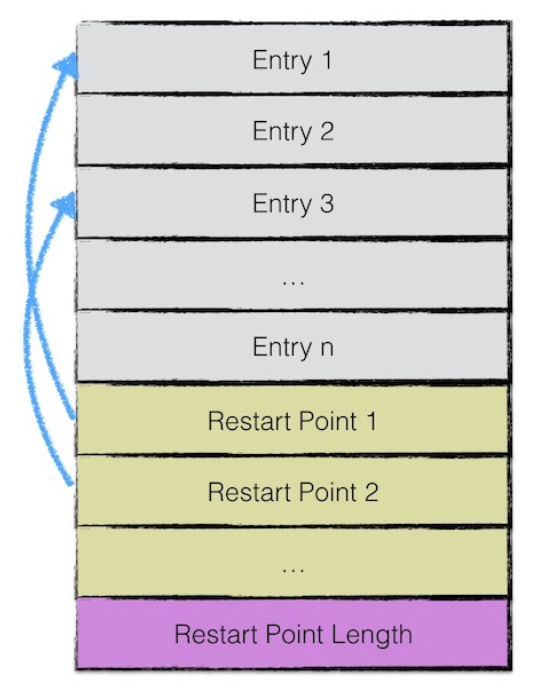
第一部分用来存储 key value 数据。由于 sstable 中所有的 key value 对都是严格按序存储的,为了节省存储空间,leveldb 并不会为每一对 key value 对都存储完整的 key 值,而是存储与上一个 key 非共享的部分,避免了 key 重复内容的存储。
每间隔若干个 key value 对,将为该条记录重新存储一个完整的 key。重复该过程(默认间隔值为16),每个重新存储完整 key 的点称之为 Restart point;
leveldb设计Restart point的目的是在读取sstable内容时,加速查找的过程。
由于每个Restart point存储的都是完整的key值,因此在sstable中进行数据查找时,可以首先利用restart point点的数据进行键值比较,以便于快速定位目标数据所在的区域;
当确定目标数据所在区域时,再依次对区间内所有数据项逐项比较key值,进行细粒度地查找;
该思想有点类似于跳表中利用高层数据迅速定位,底层数据详细查找的理念,降低查找的复杂度。

一个 entry 分为5部分内容:
- 与前一条记录 key 共享部分的长度;
- 与前一条记录 key 不共享部分的长度;
- value 长度;
- 与前一条记录 key 非共享的内容;
- value 内容;
那么当接收到一个 {key, value} pair 的时候,怎么把它编码成一个 Entry 呢?
代码展示:
1 | void BlockBuilder::Add(const Slice& key, const Slice& value) { |
我们可以把 BlockBuilder 看作是一个 Block 的建造者,它的职责就是建造一个 Block;
现在来看看它是怎么建造 data block 的:
- 首先它会判断是否需要开启一个新的 restart point;如果是,那么它是一个完整的 key,因此
shared key length = 0;如果不是则需要确定共享 key 的长度; - 根据共享 key 的长度制作 Entry
- 把 Entry 序列化到 buffer 中
当一个 data block 达到一定阈值的时候,就可以 restart points 以及 restart points length 也序列化到结尾,如下代码所示:
1 | Slice BlockBuilder::Finish() { |
那么什么时候调用 BlockBuilder::Finish 呢?从 TableBuilder::Add 中可见端倪:
1 | void TableBuilder::Add(const Slice& key, const Slice& value) { |
当 data_block 当前占用空间大小 >= 系统设定的阈值时,就进行 Flush,那么 Flush 会调用 WriteBlock,看一下它的实现:
1 | void TableBuilder::WriteBlock(BlockBuilder* block, BlockHandle* handle) { |
- 它直接调用了 BlockBuilder::Finish,得到了序列化后的 data block;
- 然后对 data block 进行压缩(大名鼎鼎的 Leveldb 竟然也是用 switch case 的方式来判断压缩算法,然后去执行压缩的。。。显然违反开闭原则);
- 最后调用 WriteRawBlock
WriteRawBlock:
1 | void TableBuilder::WriteRawBlock(const Slice& block_contents, |
可以看到它就是在 data block 后面追加了一个 compression type 和 CRC 校验码,就如图1所示;
Index Block
index block 用来存储所有 data block 的相关索引信息
index block 包含若干条 Entry,每一条 Entry 代表一个 data block 的索引信息。
一条索引包括以下内容:
- data block i 中最大的 key 值;
- 该 data block 起始地址在 sstable 中的偏移量;
- 该 data block 的大小;
这三部分内容最终会被制作成一条 Entry,并追加到 Index Block 中去;
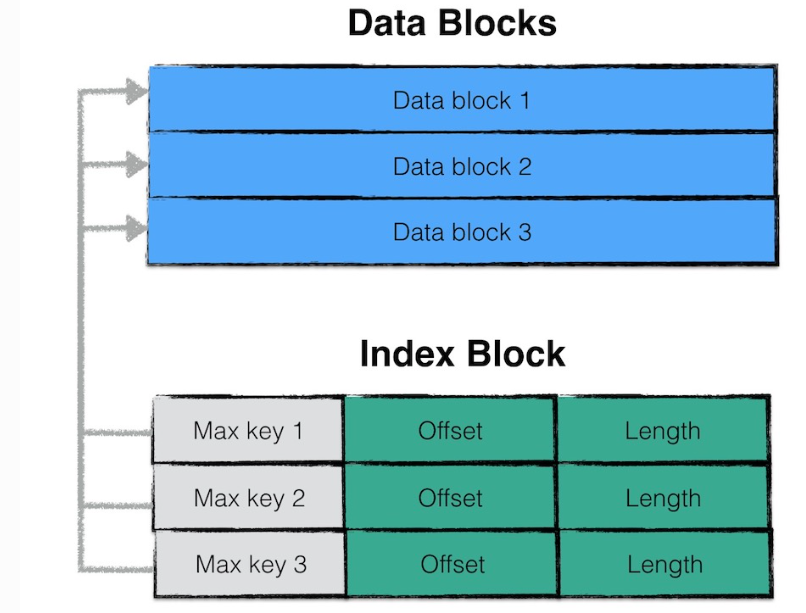
其中,data block i最大的key值还是index block中该条记录的key值。
如此设计的目的是,依次比较index block中记录信息的key值即可实现快速定位目标数据在哪个data block中。
在源码中,涉及到 Index Block 的数据变量有:
1 | BlockBuilder index_block; // DOC: 就是 sstable 逻辑结构中的 Index Block |
具体什么时候往 Index Block 追加索引 entry 呢?Leveldb 为了在 entry 中使用更短的 key,它将 index block entry 的制作时机推迟到下一个块 block data i + 1 插入第一个 key 的时候,这样它就能找到一个更短的 key 使得 key >= block data i 中最大的 key,并且 key < block data i + 1 中最小的 key;
注释:
// We do not emit the index entry for a block until we have seen the
// first key for the next data block. This allows us to use shorter
// keys in the index block. For example, consider a block boundary
// between the keys “the quick brown fox” and “the who”. We can use
// “the r” as the key for the index block entry since it is >= all
// entries in the first block and < all entries in subsequent
// blocks.
因此在 TableBuilder::Add 中进行 index block entry 的制作:
1 | void TableBuilder::Add(const Slice& key, const Slice& value) { |
这里 pending_handle 会在 TableBuilder::WriteRawBlock 函数调用时(即一个 data block 需要被 flush 到 sstable 时)记住每个 data block 在 是stable
中的偏移位置及其大小;
可以看到索引记录(handle_encoding)通过 BlockBuilder::Add 的方式追加到 Index Block 中,所以它也是被制作成了 Entry 格式的;
Filter Block
为了加快 sstable 中数据查询的效率,在直接查询 data block 中的内容之前,leveldb 首先根据 filter block 中的过滤数据判断指定的 data block 中是否有需要查询的数据,若判断不存在,则无需对这个 data block 进行数据查找
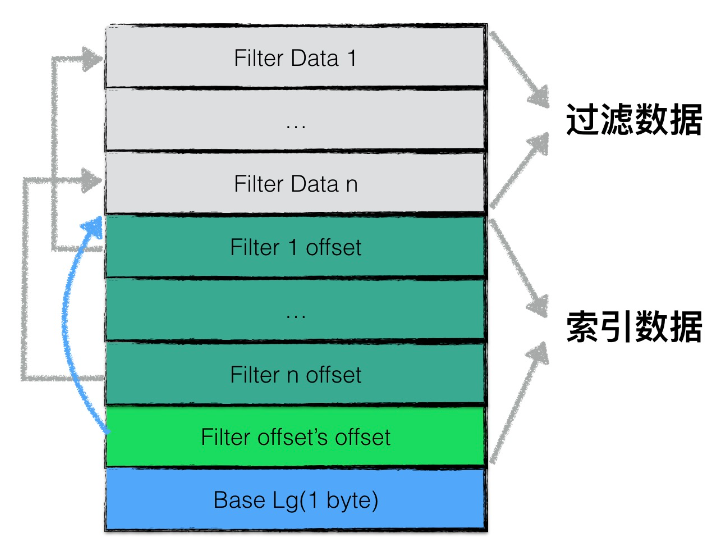
filter block 存储的是 data block 数据的一些过滤信息。这些过滤数据一般指代布隆过滤器的数据,用于加快查询的速度;
filter block存储的数据主要可以分为两部分:(1)过滤数据(2)索引数据。
其中索引数据中,filter i offset 表示第 i 个 filter data 在整个 filter block 中的起始偏移量,filter offset's offset 表示filter block的索引数据在 filter block 中的偏移量
在读取 filter block 中的内容时,可以首先读出 filter offset's offset 的值,然后依次读取 filter i offset,根据这些 offset 分别读出filter data
Base Lg 默认值为11,表示每 2KB 的数据,创建一个新的过滤器来存放过滤数据;
一个 sstable 只有一个 filter block,其内存储了所有 block 的 filter 数据;具体来说,filter data k 包含了所有起始位置处于 [basek, base(k+1)) 范围内的 block 的 key 的集合的 filter 数据,按数据大小而非 block 切分主要是为了尽量均匀,以应对存在一些 block 的 key 很多,另一些 block 的 key 很少的情况;
在 leveldb 中,怎么建造一个 Filter Block 呢?它是通过 FilterBlockBuilder 这个类来实现的:
1 | class FilterBlockBuilder { |
为了可扩展性(支持多种过滤策略)它接受一个 FilterPolicy 指针;整个建造过程需要顺序调用 StartBlock、AddKey、Finish;
每次新建一个 data block 的时候都会调用 FilterBlockBuilder::StartBlock
1 | static const size_t kFilterBaseLg = 11; |
这段代码其实就是每 2KB 用 GenerateFilter 创建一个新的 Filter;
1 | void FilterBlockBuilder::GenerateFilter() { |
FilterBlockBuilder::GenerateFilter 就是把 keys_ 中的内容追加到 result_ 中去,并且制作 Filter offset;其实这部分没有看明白~~之后再说
footer结构
footer 大小固定,为 48 字节,用来存储 meta index block 与 index block 在 sstable 中的索引信息,另外尾部还会存储一个 magic word,内容为:”http://code.google.com/p/leveldb/"字符串 sha1哈希的前 8 个字节。