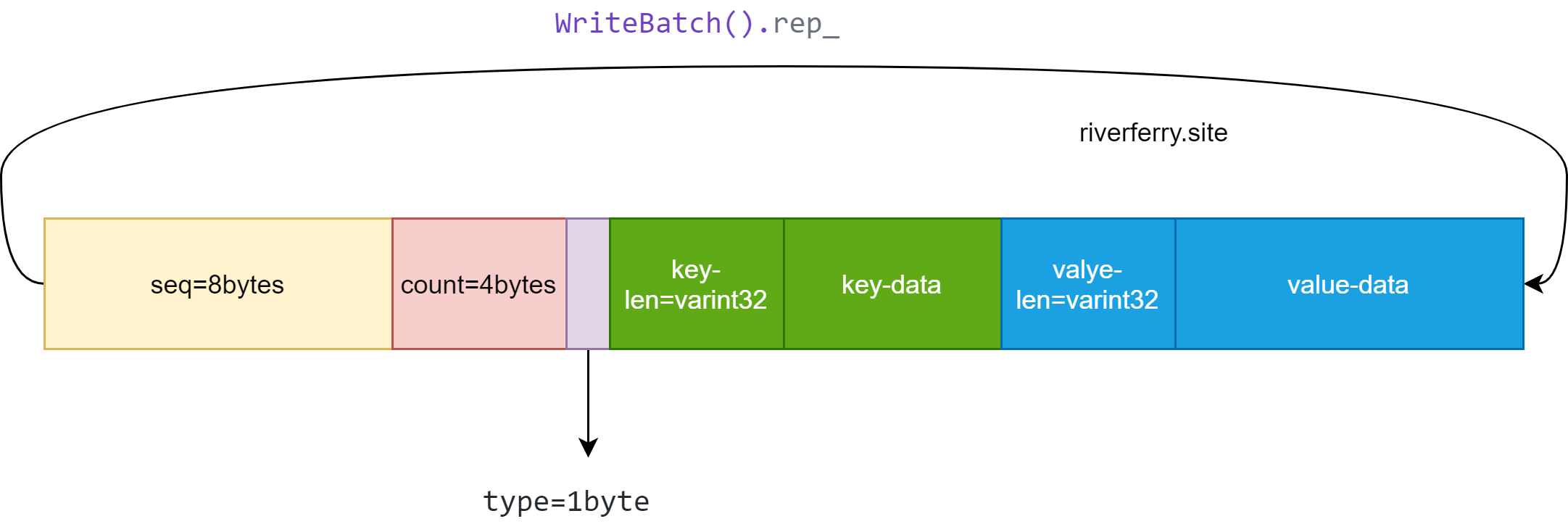
WriteBatch* DBImpl::BuildBatchGroup(Writer** last_writer){ ... ... Writer* first = writers_.front(); WriteBatch* result = first->batch; // 把能够整合的 WriteBatch 都整合到一个 batch 里面 auto max_size = // 自定义能整合得到的最大 batch 的 size *last_writer = first; std::deque<Writer*>::iterator iter = writers_.begin(); ++iter; // Advance past "first" for (; iter != writers_.end(); ++iter) { Writer* w = *iter; if (w->sync && !first->sync) { // 这里是指不要把同步 write 的内容整合进来 // Do not include a sync write into a batch handled by a non-sync write. break; }
if (w->batch != nullptr) { size += WriteBatchInternal::ByteSize(w->batch); if (size > max_size) { // Do not make batch too big break; } // 开始整合,就是把 其他的 WriteBatch 中的除了 header 的数据全部 append 到一个 WriteBatch 中去 // Append to *result if (result == first->batch) { // Switch to temporary batch instead of disturbing caller's batch result = tmp_batch_; assert(WriteBatchInternal::Count(result) == 0); WriteBatchInternal::Append(result, first->batch); } WriteBatchInternal::Append(result, w->batch); } *last_writer = w; } return result; }
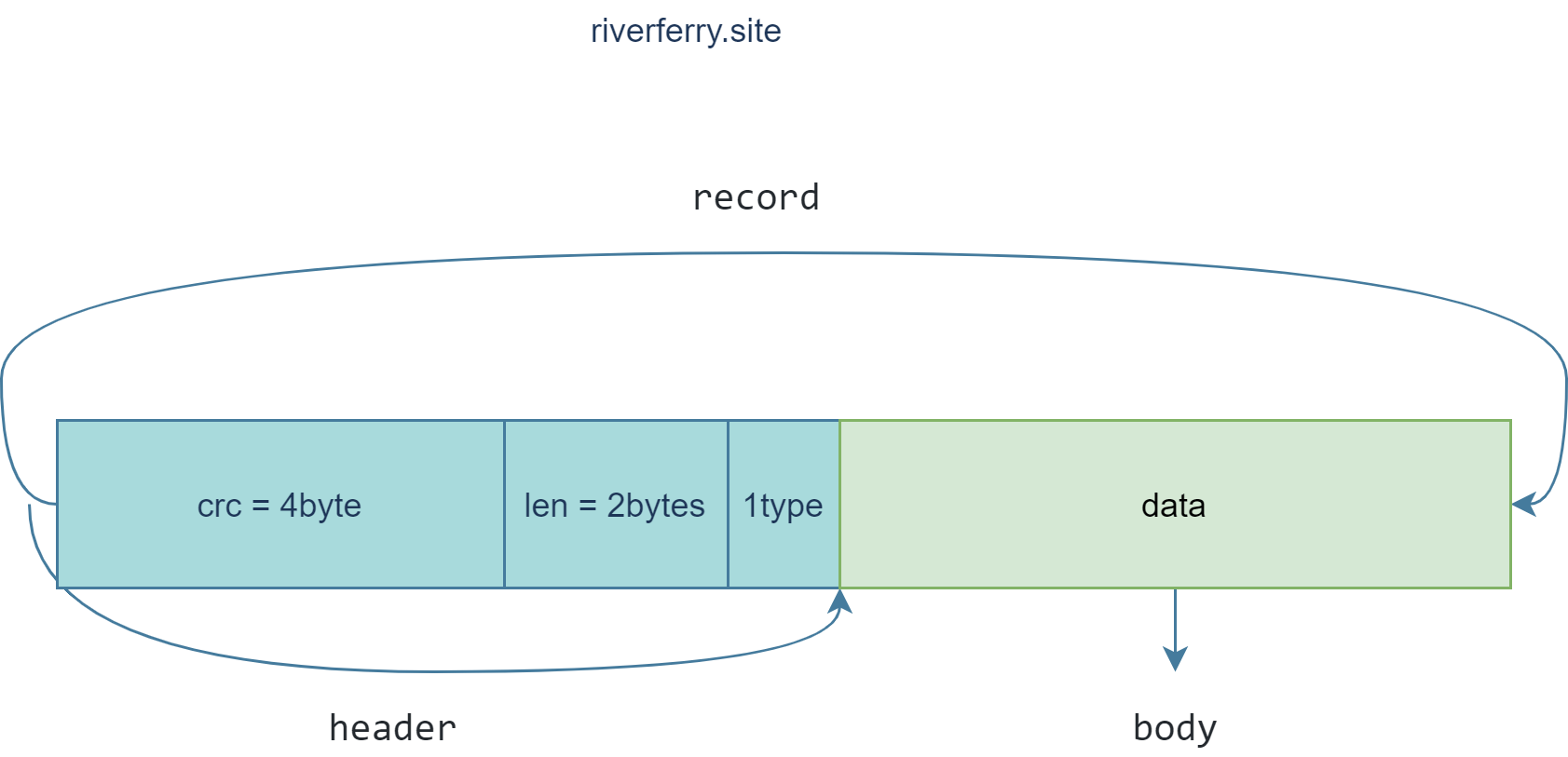
Status Writer::AddRecord(const Slice& slice){ constchar* ptr = slice.data(); size_t left = slice.size();
// Fragment the record if necessary and emit it. Note that if slice // is empty, we still want to iterate once to emit a single // zero-length record Status s; bool begin = true; do { constint leftover = kBlockSize - block_offset_; assert(leftover >= 0); if (leftover < kHeaderSize) { // Switch to a new block if (leftover > 0) { // Fill the trailer (literal below relies on kHeaderSize being 7) static_assert(kHeaderSize == 7, ""); dest_->Append(Slice("\x00\x00\x00\x00\x00\x00", leftover)); } block_offset_ = 0; }
// Invariant: we never leave < kHeaderSize bytes in a block. assert(kBlockSize - block_offset_ - kHeaderSize >= 0);