
故障可恢复事务
2022年7月16日
故障可恢复事务
虽然没学过数据库的使用,但是它本身作为一个系统,它也必定遵守系统开发的基本概念,例如,容错,故障自动恢复,持久化等;
看了 MIT 莫里斯 大佬的课程,记录下一个简单的事务数据库的设计思想
事务
事务的特性 ACID,在网上资料多的是;
- 原子性
- 一致性
- 隔离性
- 持久性
大佬是这样介绍事务的:
事务把一些列操作打包成一个原子操作,并顺序执行这些操作;
举例:例如一个银行系统,有一个转账的操作;X 转账 10 块钱给 Y;用事务表示就是:
1 | BEGIN |
我们希望数据库有这样的效果:
- 能顺序地执行这些操作,并且不允许客户看到执行的中间状态;
- 同时,我们还要允许系统发生故障,在故障恢复后,事务中的所有操作要么全部被执行,要不全部都没有执行;
- 当数据库重启后数据不会丢失;
怎么实现事务
概念上:事务通过对涉及到的每一份数据加锁来实现。在整个事务的过程中,都对 X,Y 加了锁。并且只有当事务结束、提交并且持久化存储之后,锁才会被释放。
具体实现:
我们考虑简单的事务数据库的实现,即 单机 + 本地磁盘 来做存储;那么数据记录都存在磁盘中,可能会用 B 树来做索引的数据结构;那么,他的结构大概是这样的;X,Y 肯定是存在于某个 disk block 中的,disk block 中一般存有很多数据,而 X,Y 仅仅占其中的某些 bits
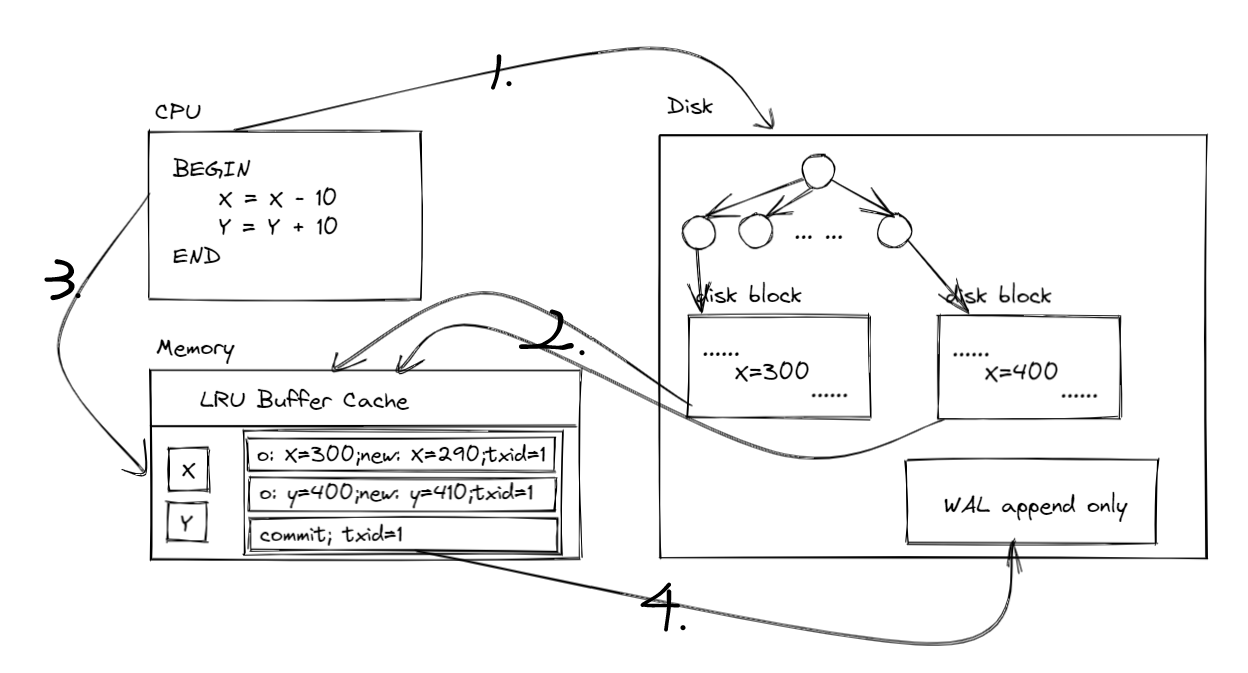
- 进程开启一个事务,然后按照索引找到具体的 disk block,为了读取 X,Y 所在的 disk block,CPU 向 Disk 驱动发读取 disk block 的命令;然后就进程进入阻塞态主动让出 CPU,等待磁盘读取完成;
- 磁盘驱动将 X,Y 所在的 disk block 加载到内存中并用 LRU Buffer Cache 缓存起来,然后通过中断通知 CPU 读任务完成;
- CPU 将原来的进程设置为就绪态,然后经过一定时间后重新得到 CPU 的使用权;对内存中的 X,Y 进行操作;首先会制作操作日志,上述的事务会产生三条日志,前两条记录了原始的(original)X 和 Y 的值,以及操作执行后(new)X,Y 的值,最后一条是 Commit 日志,表示着整个事务的结束,并提交;在同一个事务中的所有日志带上事务 ID,用于唯一辨别一个事务;
- 进程将操作日志 flush 到 Disk(这里可能是 lazy flush,等累计了足够多的事务日志后再一次性 flush),然后更新 X,Y 在内存中的值,并响应客户成功执行了一个事务;
故障分析
接下来有两种情况:
如果数据库没有崩溃
那么在它的内存中,X,Y 对应的数值分别是 290 和 410;最终数据库会将内存中的数值写入到磁盘对应的位置
如果数据库在将内存中的数值写入到磁盘之前就崩溃了
这样磁盘中的 disk block 中仍然是旧的数值。当数据库重启时,恢复软件会扫描 WAL 日志,发现对应事务的 log,并发现事务的commit 记录,那么恢复软件会将新的数值写入到磁盘中。这被称为 redo/replay,它会重新执行事务中的写操作