
多线程下 fork 与 exit 引发的连锁错误
多线程下 fork 与 exit 引发的连锁错误
这篇文章存在问题!!!
问题出现在这样的情景下:
编译完 loggerTest.cpp 后,执行后,程序被阻塞不能退出,在通过 ps aux|grep ./loggerTest 一看,好家伙,原来是 asyncLogging.cpp 中的rollFile 函数 fork 出来的进程都还没释放掉,而且都处在 S 状态,也就是被阻塞了!

本来 fork 出这个进程是为了 roll file 的,也就是把 log 文件进行压缩打包用的。代码片段如下:
1 | ... |
可以看到本来的预期是 fork 出一个子进程后,立马 execv 让可执行文件 jiaoben 来覆盖原来的内容(包括页表,各种锁、条件变量的状态,当然还有内核数据结构)。jiaoben 这个可执行文件就是用来执行 python 脚本的,照理说执行完会立马退出的呀!
好在这个进程没退出,我们可以用 gdb 来追踪它的状态:
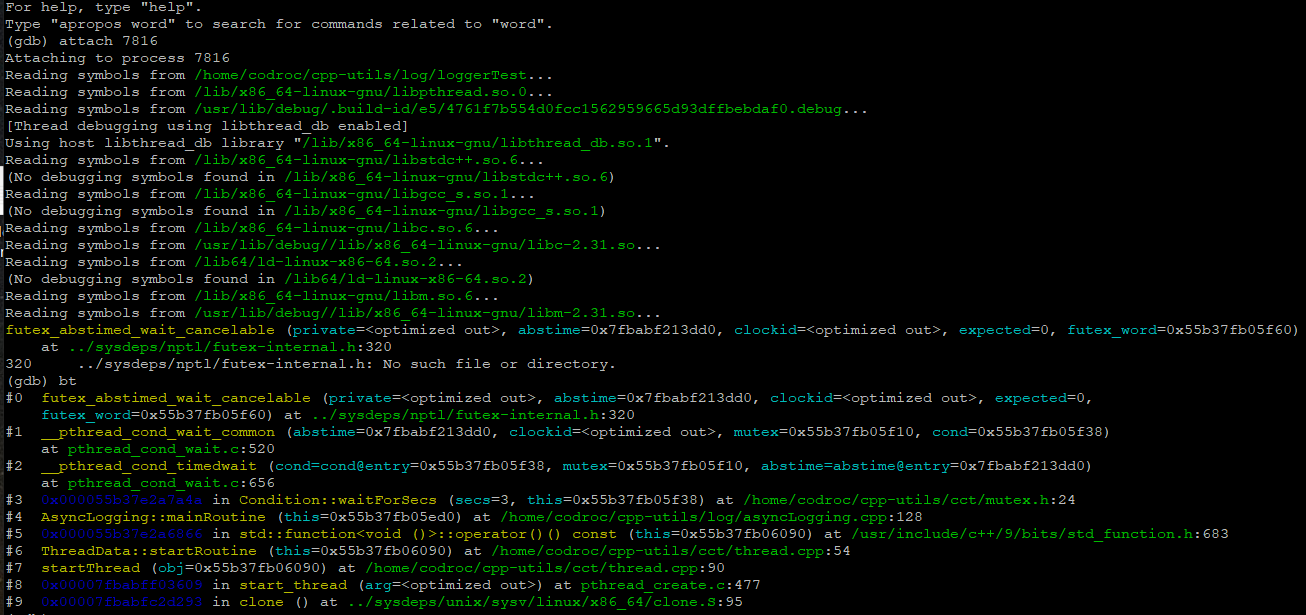
这是妥妥的连 execv 都没执行成功呀(因为 如果没有子进程 wait(0) 会直接返回 -1,所以子进程相当于继续执行下去了)!然后一看目录下,我晕,jiaoben.cpp 忘记编译了,所以 execv 执行失败,后端日志线程就回到 while 循环了,一直执行 _cond.waitForSecs(3); 这也就导致该进程在 ps 命令中看上去一直被阻塞了!
这也是血的教训呀!每次调用函数后一定要判断是否调用成功!不然有的苦头吃啊~~接下来,自然地将代码改成如下片段:
1 | ... |
很自然呀!如果 execv 执行失败,让它退出就行了!但是好像并没那么容易,再次执行 loggerTest,发现连该进程都被阻塞了。当即用 ps aux|grep ./loggerTest 查看后,发现有两个名为loggerTest 的进程处在运行状态,退不出去!那没事,只要你还活着,我就能用 gdb attach 到你~~继续使用 gdb 去查看哪里出错了:
这一个 gdb 追踪的是原始的 ./loggerTest 进程,因为它有 2 个线程,而 fork 只能 fork 出一个线程。
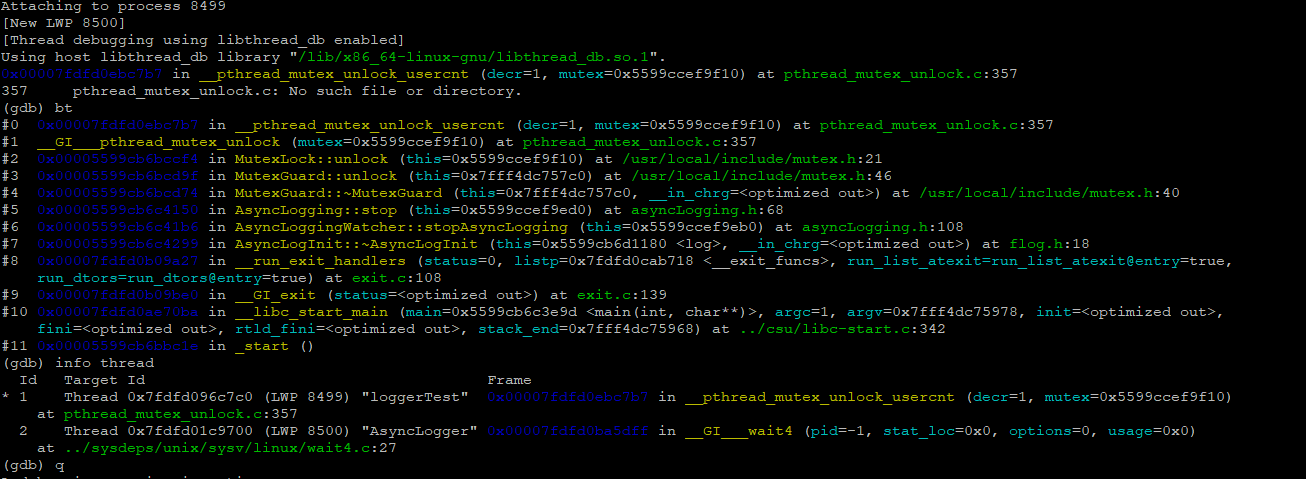
可以看到测试进程./loggerTest 的主线程一直在 AsyncLogging::stop 上:
1 | void stop() { |
而这个函数一直停留在 stop 中的唯一理由就是一直在 while 循环内出不去,也就是 wakeup 没作用,日志后端线程根本不鸟这个 wakeup。
再来看看打包日志的进程,它又是为什么迟迟不肯退出呢?
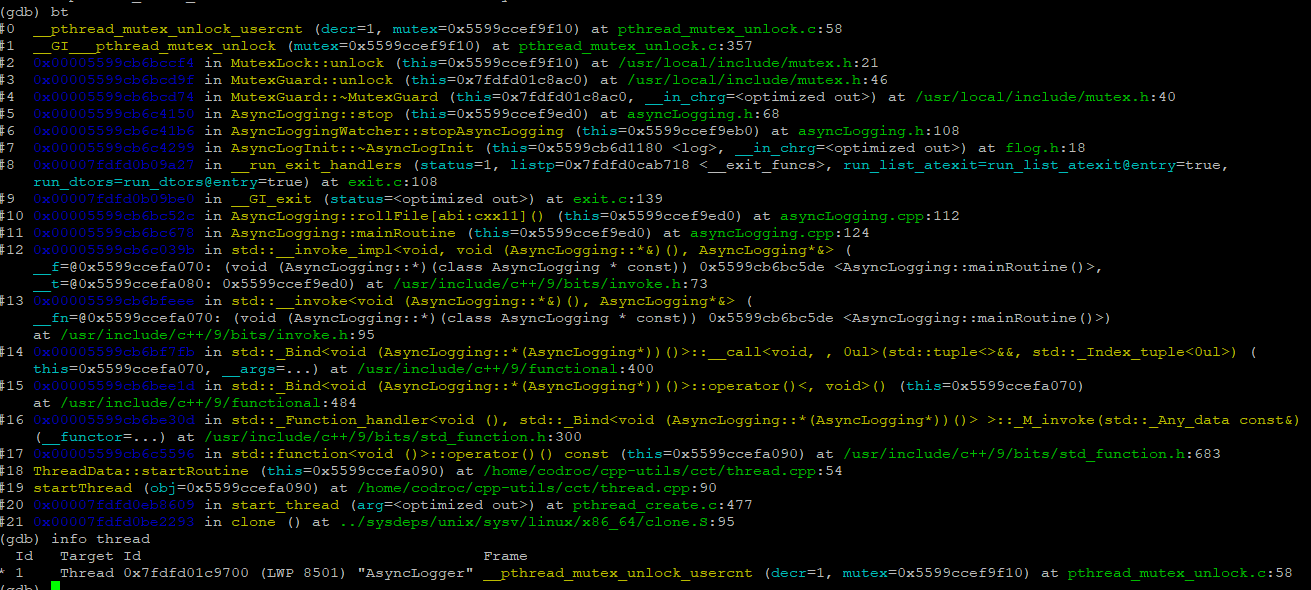
可以看到它也一直停留在 AsyncLogging::stop 上。并且这个进程只有一个线程,那么这个 wakeup 就很搞笑了呀,因为根本没有接收者,或者说接收这个 wakeup 的人就是你自己,而你此时在 while 循环里永远也接收不到。再回到 roll file 的代码片段,它是一直阻塞等待着子进程退出才会继续执行下去的,然而此时子进程(打包日志的进程)永远也退不出,这就导致了 ./loggerTest 进程的后端日志线程永远被阻塞(可以通过 gdb 查看 thread 2 阻塞的位置就知道了 __GI__wait4),
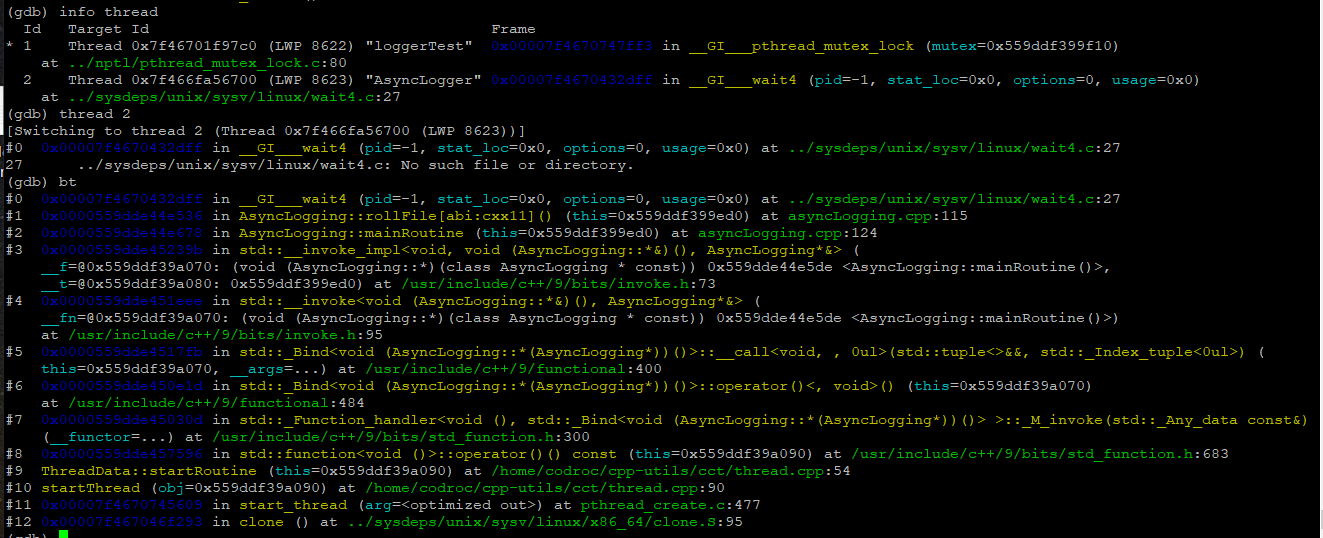
进而导致前端日志线程退出时执行 AsyncLogging::stop 的 wakeup 却得不到后端日志线程的响应(因为它一直 wait(0) 等着子进程退出),这一系列连锁反应就导致了现在的尴尬局面~~
该怎么解决?那就是让 execv 一定要执行成功,在执行前判断脚本文件是否存在,如果不存在则不要在多线的情况下去 fork 了,很容易造成复杂的错误!
带来的启发
- 在多线程环境下,调用 fork 后一定要立马确定 execv 成功,不然的话很容易出现复杂难以诊断的错误。因为 fork 在 linux 环境下只会 fork 出一个线程,这样本质上就和 锁,条件变量 等待同步工具在概念上矛盾了(同步工具用于多线程环境,而 fork 出来的是单线程进程)。
- 不要以为调用了 exit 后 os 一定就会帮你释放掉资源,因为在 C++ 中,还存在全局对象析构这么一个环节,很有可能在这个环节 整个进程就阻塞住了,进而导致资源得不到释放,慢慢的把你的内存吃光!!!